CS186 RookieDB Storage Layer
本文内容:讲解rookiedb中一张表是如何存储在磁盘上的,涉及到databox、io和table三个字模块。
Field
从层次上看,库是由若干张表组成,表是由若干个记录组成,记录由若干个列(字段)组成,所以列是数据库中数据的最小单位。
在数据库中,列是有类型的,每一列的类型是建表的时候确定的。
在rookiedb中,databox模块就定义了所支持的所有字段类型:
- Bool
- ByteArray
- Float
- Int
- Long
- String
其中,Bool、Float、Int、Long分别与Java中的boolean、float、int、long类型对应,它们所占用的字节数都是确定的,这应该不需要多做解释。
ByteArray和String是两个稍微特殊的类型,其中ByteArray是一个byte数组,在定义ByteArray的时候就需要指定这个数组的长度。在进行写入的时候,byte数组的长度要与定义的长度严格相等, 否则就会报错。(也可以认为ByteArray中长度也是类型的一部分,不同长度的ByteArray是不同的类型)。
public class ByteArrayDataBox extends DataBox {
byte[] bytes;
public ByteArrayDataBox(byte[] bytes, int n) {
if (bytes.length != n) {
throw new RuntimeException("n must be equal to the length of bytes");
}
this.bytes = bytes;
}
@Override
public byte[] toBytes() {
return this.bytes;
}
}
String与ByteArray类似,可以把它看作一个CharArray。在定义String的时候也要提供一个长度,在写入的时候,如果提供的字符串长度不够,则会进行填充;如果提供的字符串长度超过了定义的长度,则会进行截断处理。
public class StringDataBox extends DataBox {
private final String s;
private final int m;
public StringDataBox(String s, int m) {
if (m <= 0) {
String msg = String.format("Cannot construct a %d-byte string. " +
"Strings must be at least one byte.", m);
throw new IllegalArgumentException(msg);
}
this.m = m;
s = m > s.length() ? s : s.substring(0, m);
this.s = s.replaceAll("\0*$", ""); // Trim off null bytes
}
@Override
public byte[] toBytes() {
// pad with null bytes
String padded = s + new String(new char[m - s.length()]);
return padded.getBytes(StandardCharsets.US_ASCII);
}
}
Record
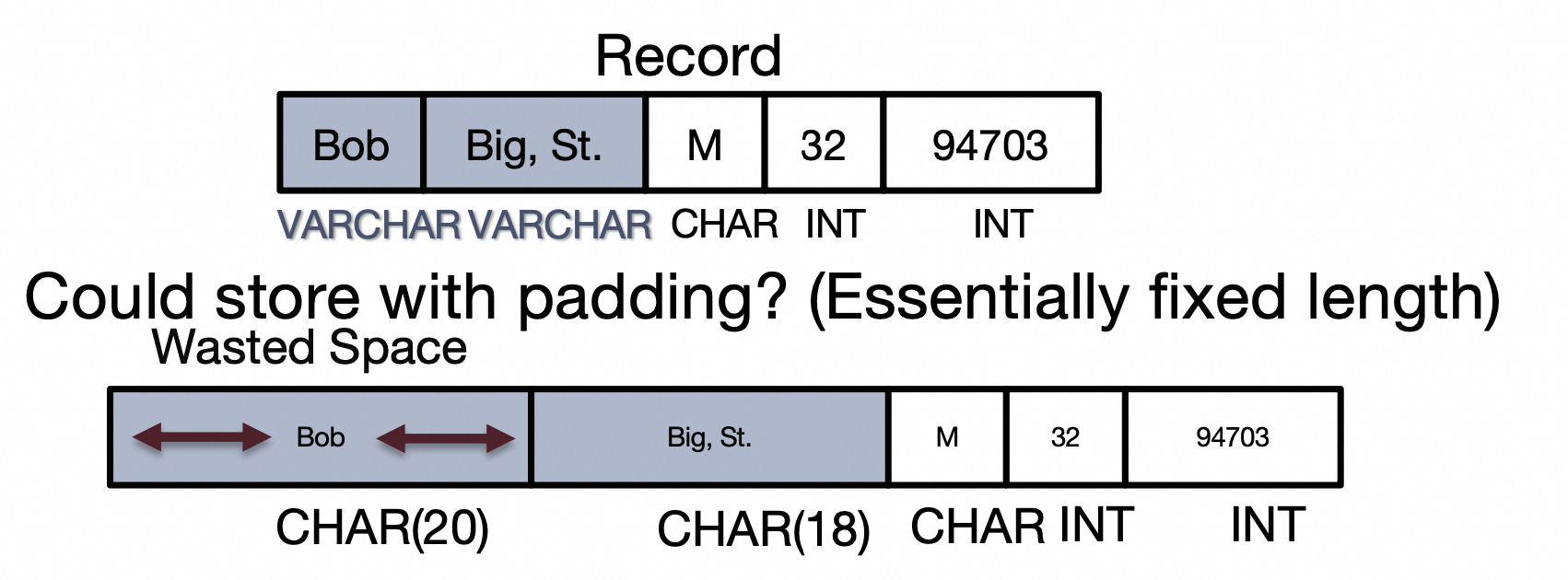
课件里讲了两种组织Record的方法,一种适合用来处理所有Field都是定长的情况(或者,对变长Field进行填充,让它等效定长),另一种适合用来处理包含变长Field的情况。
第一种:各个Field依次排列,填充变长Field
第二种:给Record增加Header,保存指向变长字段的指针
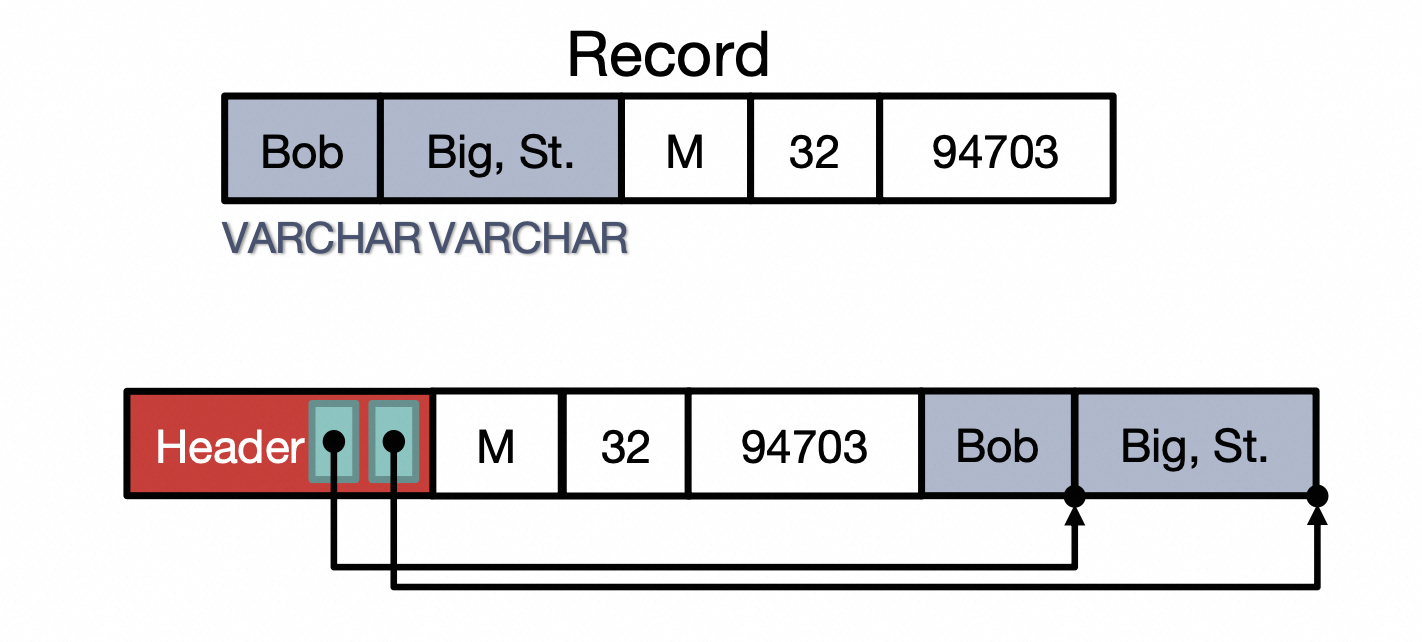
由于rookiedb中所有Field都是等效定长的(这样做主要是为了实现简单),所以采用第一种方式。
在rookiedb中,一行数据就是一个Record,一个Record就是一个DataBoxed的list。
/** A Record is just list of DataBoxes. */
public class Record {
private final List<DataBox> values;
public Record(List<DataBox> values) {
this.values = values;
}
}
需要重点关注的是Record的序列化和反序列化。
序列化方法如下,很简单,首先通过Schema计算出Record所占的字节数,然后申请一个ByteBuffer,依次将
/**
* Serializes this Databox into a byte array based on the passed in schema.
*/
public byte[] toBytes(Schema schema) {
ByteBuffer byteBuffer = ByteBuffer.allocate(schema.getSizeInBytes());
for (DataBox value : values) {
byteBuffer.put(value.toBytes());
}
return byteBuffer.array();
}
反序列化:根据Schema,依次将各个Field读取出来。从这里可以看到,Schema非常重要,没有Schema,数据就是一堆没有意义的01串。
/**
* Takes a byte[] and decodes it into a Record. This method assumes that the
* input byte[] represents a record that corresponds to this schema.
*
* @param buf the byte array to decode
* @param schema the schema used for this record
* @return the decoded Record
*/
public static Record fromBytes(Buffer buf, Schema schema) {
List<DataBox> values = new ArrayList<>();
for (Type t : schema.getFieldTypes()) {
values.add(DataBox.fromBytes(buf, t));
}
return new Record(values);
}
Table
一个Table有若干Record组成,这些Record占用若干个Page,所以如何组织这个Table内的这些Record,也是有说法的。
课件主要讲解了两种组织Record的方法:基于bitmap和基于slotted array。
基于bitmap的方法:
这种方法的优点是实现起来很简单,插入record的时候仅仅需要遍历bitmap,找到一个空闲bit,然后在相应的位置写入即可。删除Record更简单,将bitmap中对应的bit清空即可。缺点是仅适用于Record定长的情况。
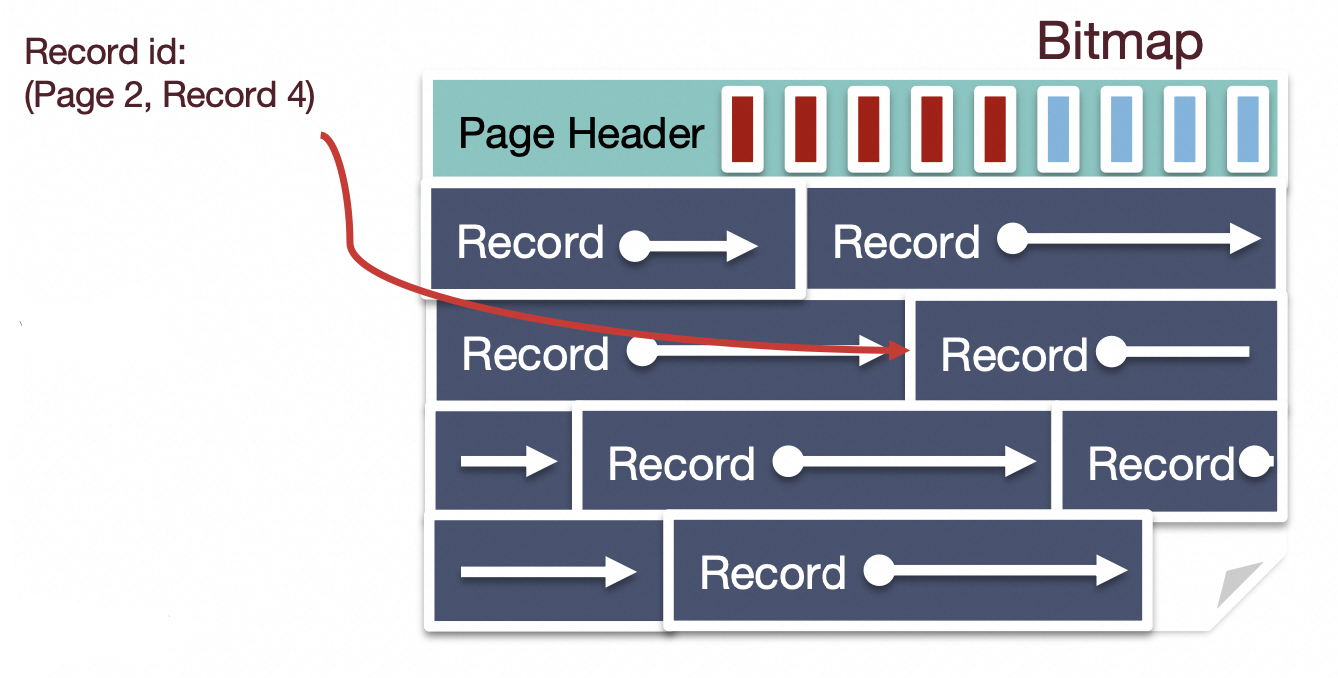
基于slotted array的方法:
slotted array应该是标准的组织Record的方法,它可以支持变长Record,但是相比于bitmap,实现起来稍显复杂。
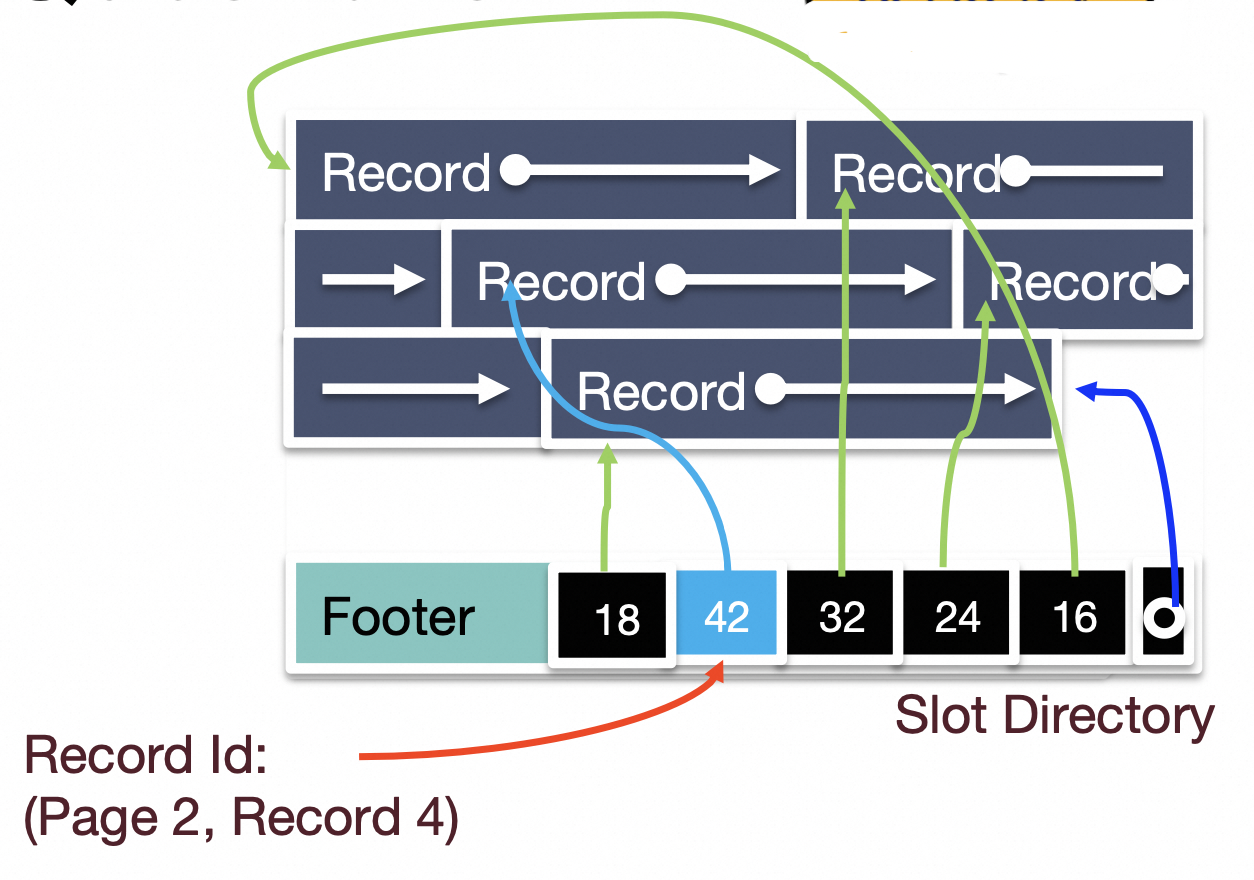
因为rookiedb的Record都是定长的,所以它采用基于bitmap的方式来组织页内record。
在创建Table的时候,可以根据Page的大小和每个Record的大小,计算出一个Page内最多放多少个Record。
注意这里每个Record的占用空间,出了Record中各个Field本身之外,还需要计算在bitmap中的一个bit。
public static int computeNumRecordsPerPage(int pageSize, Schema schema) {
int schemaSize = schema.getSizeInBytes();
if (schemaSize > pageSize) {
throw new DatabaseException(String.format(
"Schema of size %f bytes is larger than effective page size",
schemaSize
));
}
if (2 * schemaSize + 1 > pageSize) {
// special case: full page records with no bitmap. Checks if two
// records + bitmap is larger than the effective page size
return 1;
}
// +1 for space in bitmap
int recordOverheadInBits = 1 + 8 * schema.getSizeInBytes();
int pageSizeInBits = pageSize * 8;
return pageSizeInBits / recordOverheadInBits;
}
有了一个Page内最多存放的Record的个数,就可以得出bitmap的大小。
private static int computeBitmapSizeInBytes(int pageSize, Schema schema) {
int recordsPerPage = computeNumRecordsPerPage(pageSize, schema);
if (recordsPerPage == 1) {
return 0;
}
if (recordsPerPage % 8 == 0) {
return recordsPerPage / 8;
}
return recordsPerPage / 8 + 1;
}
后续在Table中插入一条Record,就很简单了:
- 找到一个有足够空间的Page
- 读出Page的bitmap,在bitmap中找到一个空闲的slot
- 在空闲处写入待插入的数据
- 更新bitmap并写回
public synchronized RecordId addRecord(Record record) {
record = schema.verify(record);
Page page = pageDirectory.getPageWithSpace(schema.getSizeInBytes());
try {
// Find the first empty slot in the bitmap.
// entry number of the first free slot and store it in entryNum; and (2) we
// count the total number of entries on this page.
byte[] bitmap = getBitMap(page);
int entryNum = 0;
for (; entryNum < numRecordsPerPage; ++entryNum) {
if (Bits.getBit(bitmap, entryNum) == Bits.Bit.ZERO) {
break;
}
}
if (numRecordsPerPage == 1) {
entryNum = 0;
}
assert (entryNum < numRecordsPerPage);
// Insert the record and update the bitmap.
insertRecord(page, entryNum, record);
Bits.setBit(bitmap, entryNum, Bits.Bit.ONE);
writeBitMap(page, bitmap);
// Update the metadata.
stats.get(name).addRecord(record);
return new RecordId(page.getPageNum(), (short) entryNum);
} finally {
page.unpin();
}
}
private synchronized void insertRecord(Page page, int entryNum, Record record) {
int offset = bitmapSizeInBytes + (entryNum * schema.getSizeInBytes());
page.getBuffer().position(offset).put(record.toBytes(schema));
}
Update也很简单,都不用更新bitmap,直接overwrite就行。
public synchronized Record updateRecord(RecordId rid, Record updated) {
validateRecordId(rid);
// If we're updating a record we'll need exclusive access to the page
// its on.
LockContext pageContext = tableContext.childContext(rid.getPageNum());
// TODO(proj4_part2): Update the following line
LockUtil.ensureSufficientLockHeld(pageContext, LockType.NL);
Record newRecord = schema.verify(updated);
Record oldRecord = getRecord(rid);
Page page = fetchPage(rid.getPageNum());
try {
insertRecord(page, rid.getEntryNum(), newRecord);
this.stats.get(name).removeRecord(oldRecord);
this.stats.get(name).addRecord(newRecord);
return oldRecord;
} finally {
page.unpin();
}
}
删除更加简单,只需要将bitmap中相应的bit置为0(维护page directory稍后会讲)。
public synchronized Record deleteRecord(RecordId rid) {
validateRecordId(rid);
LockContext pageContext = tableContext.childContext(rid.getPageNum());
// TODO(proj4_part2): Update the following line
LockUtil.ensureSufficientLockHeld(pageContext, LockType.NL);
Page page = fetchPage(rid.getPageNum());
try {
Record record = getRecord(rid);
byte[] bitmap = getBitMap(page);
Bits.setBit(bitmap, rid.getEntryNum(), Bits.Bit.ZERO);
writeBitMap(page, bitmap);
stats.get(name).removeRecord(record);
int numRecords = numRecordsPerPage == 1 ? 0 : numRecordsOnPage(page);
pageDirectory.updateFreeSpace(page,
(short) ((numRecordsPerPage - numRecords) * schema.getSizeInBytes()));
return record;
} finally {
page.unpin();
}
}
PageDirecotry
上面讲了如何在一个Page内组织多个Record,但是Table肯定不止占用一个Page,这样就带来了一个问题:如何组织这些Page?
课件里介绍了几种组织方式:
- Unordered Heap Files:Record在Pages中可以随意放在任意一个位置
- Clustered Heap Files:Record和Page按照某种有意义的方式组织起来
- Sorted Files:Record和Page之间有一个严格的顺序
- Index Files:索引文件,保存指向主表的索引
rookiedb选择了Unordered Heap Files来组织所有的Page。
关于Unordered Heap Files,课件里介绍了两种实现:
- 基于链表:将所有的Data Page组织成两个链表(Full Page List & Free Page List)。这种方式的缺点主要是插入数据的时候可能需要遍历整个链表,这样就会造成非常多的I/O,这在实际使用中是不能接受的。
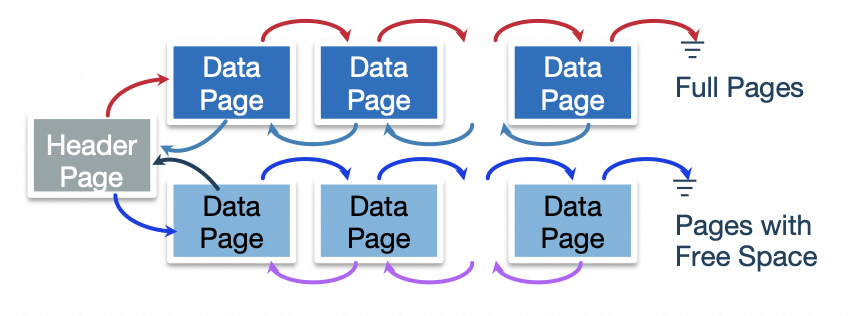
- 基于Directory:HeaderPage中包含若干Entry,每个Entry对应一个DataPage,保存了DataPage的一些元数据和指针。在插入数据的时候,只需要查看Header Page中的Entry,就可以知道这个Data Page上有没有足够的剩余空间。Header Page之间组织成一个链表,并且常驻内存,这样就可以极大的减少I/O次数。
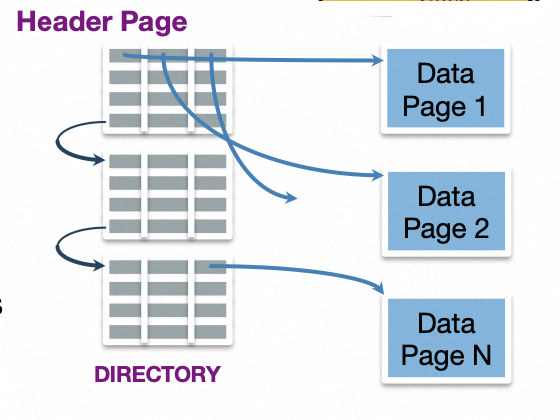
rookiedb实现了PageDirectry,每一个PageDirectory管理一组Data Page,对应磁盘上的一个文件。
下面是PageDirectory的构造函数,其中的partNum是与磁盘文件对应的(稍后磁盘管理会讲)。
/**
* Creates a new heap file, or loads existing file if one already
* exists at partNum.
* @param bufferManager buffer manager
* @param partNum partition to allocate new header pages in (can be different partition
* from data pages)
* @param pageNum first header page of heap file
* @param emptyPageMetadataSize size of metadata on an empty page
* @param lockContext lock context of this heap file
*/
public PageDirectory(BufferManager bufferManager, int partNum, long pageNum,
short emptyPageMetadataSize, LockContext lockContext) {
this.bufferManager = bufferManager;
this.partNum = partNum;
this.emptyPageMetadataSize = emptyPageMetadataSize;
this.lockContext = lockContext;
this.firstHeader = new HeaderPage(pageNum, 0, true);
}
HeaderPage的layout:
- MetaData
- 1 byte: 0x1, indicate this is a valid header page
- 4 bytes: page directory id
- 8 bytes: next header page id
- Data
- 10 bytes: date page entry
- …
HeaderPage的构造函数涉及到对HeaderPage进行反序列化的方法:首先使用MetaData最开始的第一个byte来检测这个PageDirectory是否是一个新的PageDirectory。然后读取/构造 PDE。
Buffer pageBuffer = this.page.getBuffer();
if (pageBuffer.get() != (byte) 1) {
byte[] buf = new byte[BufferManager.EFFECTIVE_PAGE_SIZE];
Buffer b = ByteBuffer.wrap(buf);
// invalid page, initialize empty header page
if (firstHeader) {
pageDirectoryId = new Random().nextInt();
}
b.position(0).put((byte) 1).putInt(pageDirectoryId).putLong(DiskSpaceManager.INVALID_PAGE_NUM);
DataPageEntry invalidPageEntry = new DataPageEntry();
for (int i = 0; i < HEADER_ENTRY_COUNT; ++i) {
invalidPageEntry.toBytes(b);
}
nextPageNum = -1L;
pageBuffer.put(buf, 0, buf.length);
} else {
// load header page
if (firstHeader) {
pageDirectoryId = pageBuffer.getInt();
} else if (pageDirectoryId != pageBuffer.getInt()) {
throw new PageException("header page page directory id does not match");
}
nextPageNum = pageBuffer.getLong();
for (int i = 0; i < HEADER_ENTRY_COUNT; ++i) {
DataPageEntry dpe = DataPageEntry.fromBytes(pageBuffer);
if (dpe.isValid()) {
++this.numDataPages;
}
}
}
PageDirectory对外提供的最重要饿一个接口是getPageWithSpace,在对表进行插入的时候会用到这个接口:
public synchronized RecordId addRecord(Record record) {
record = schema.verify(record);
Page page = pageDirectory.getPageWithSpace(schema.getSizeInBytes());
//...
// Insert the record and update the bitmap.
insertRecord(page, entryNum, record);
Bits.setBit(bitmap, entryNum, Bits.Bit.ONE);
writeBitMap(page, bitmap);
//...
}
getPageWithSpace的实现方法,就是遍历HeaderPage链表,找到一个满足条件的DPE:
public Page getPageWithSpace(short requiredSpace) {
if (requiredSpace <= 0) {
throw new IllegalArgumentException("cannot request nonpositive amount of space");
}
if (requiredSpace > EFFECTIVE_PAGE_SIZE - emptyPageMetadataSize) {
throw new IllegalArgumentException("requesting page with more space than the size of the page");
}
Page page = this.firstHeader.loadPageWithSpace(requiredSpace);
LockContext pageContext = lockContext.childContext(page.getPageNum());
// TODO(proj4_part2): Update the following line
LockUtil.ensureSufficientLockHeld(pageContext, LockType.NL);
return new DataPage(pageDirectoryId, page);
}
首先搜索第一个Header Page,读取所有的DPE,然后查看这个DPE对应的DataPage上是否还有足够的剩余空间。
如果所有的DataPage都不满足条件,那么尝试找一个空闲的DPE,申请一个DataPage。
如果整个HeaderPage所管理的所有DataPage都不满足条件,并且没有办法申请新的DataPage,就转到下一个HeaderPage。
// gets and loads a page with the required free space
private Page loadPageWithSpace(short requiredSpace) {
this.page.pin();
try {
Buffer b = this.page.getBuffer();
b.position(HEADER_HEADER_SIZE);
// if we have any data page managed by this header page with enough space, return it
short unusedSlot = -1;
for (short i = 0; i < HEADER_ENTRY_COUNT; ++i) {
DataPageEntry dpe = DataPageEntry.fromBytes(b);
if (!dpe.isValid()) {
if (unusedSlot == -1) {
unusedSlot = i;
}
continue;
}
if (dpe.freeSpace >= requiredSpace) {
dpe.freeSpace -= requiredSpace;
b.position(b.position() - DataPageEntry.SIZE);
dpe.toBytes(b);
return bufferManager.fetchPage(lockContext, dpe.pageNum);
}
}
// if we have any unused slot in this header page, allocate a new data page
if (unusedSlot != -1) {
Page page = bufferManager.fetchNewPage(lockContext, partNum);
DataPageEntry dpe = new DataPageEntry(page.getPageNum(),
(short) (EFFECTIVE_PAGE_SIZE - emptyPageMetadataSize - requiredSpace));
b.position(HEADER_HEADER_SIZE + DataPageEntry.SIZE * unusedSlot);
dpe.toBytes(b);
page.getBuffer().putInt(pageDirectoryId).putInt(headerOffset).putShort(unusedSlot);
++this.numDataPages;
return page;
}
// if we have no next header page, make one
if (this.nextPage == null) {
this.addNewHeaderPage();
}
// no space on this header page, try next one
return this.nextPage.loadPageWithSpace(requiredSpace);
} finally {
this.page.unpin();
}
}
在删除record的时候,需要更新DataPage对应的DPE:
public synchronized Record deleteRecord(RecordId rid) {
validateRecordId(rid);
LockContext pageContext = tableContext.childContext(rid.getPageNum());
// TODO(proj4_part2): Update the following line
LockUtil.ensureSufficientLockHeld(pageContext, LockType.NL);
Page page = fetchPage(rid.getPageNum());
try {
Record record = getRecord(rid);
byte[] bitmap = getBitMap(page);
Bits.setBit(bitmap, rid.getEntryNum(), Bits.Bit.ZERO);
writeBitMap(page, bitmap);
stats.get(name).removeRecord(record);
int numRecords = numRecordsPerPage == 1 ? 0 : numRecordsOnPage(page);
pageDirectory.updateFreeSpace(page,
(short) ((numRecordsPerPage - numRecords) * schema.getSizeInBytes()));
return record;
} finally {
page.unpin();
}
}
更新DPE的方法,就是读取DataPage的元数据,找到对应的HeaderPage和DPE的offset,然后更新写对应的DPE:
public void updateFreeSpace(Page page, short newFreeSpace) {
if (newFreeSpace <= 0 || newFreeSpace > EFFECTIVE_PAGE_SIZE - emptyPageMetadataSize) {
throw new IllegalArgumentException("bad size for data page free space");
}
int headerIndex;
short offset;
page.pin();
try {
Buffer b = ((DataPage) page).getFullBuffer();
b.position(4); // skip page directory id
headerIndex = b.getInt();
offset = b.getShort();
} finally {
page.unpin();
}
HeaderPage headerPage = firstHeader;
for (int i = 0; i < headerIndex; ++i) {
headerPage = headerPage.nextPage;
}
headerPage.updateSpace(page, offset, newFreeSpace);
}
// updates free space
private void updateSpace(Page dataPage, short index, short newFreeSpace) {
this.page.pin();
try {
if (newFreeSpace < EFFECTIVE_PAGE_SIZE - emptyPageMetadataSize) {
// write new free space to disk
Buffer b = this.page.getBuffer();
b.position(HEADER_HEADER_SIZE + DataPageEntry.SIZE * index);
DataPageEntry dpe = DataPageEntry.fromBytes(b);
dpe.freeSpace = newFreeSpace;
b.position(HEADER_HEADER_SIZE + DataPageEntry.SIZE * index);
dpe.toBytes(b);
} else {
// the entire page is free; free it
Buffer b = this.page.getBuffer();
b.position(HEADER_HEADER_SIZE + DataPageEntry.SIZE * index);
(new DataPageEntry()).toBytes(b);
bufferManager.freePage(dataPage);
}
} finally {
this.page.unpin();
}
}
Database
从Database的构造函数可以看到,每一个Database需要和一个dir对应:
/**
* Creates a new database with recovery disabled (DummyRecoveryManager)
*
* @param fileDir the directory to put the table files in
* @param numMemoryPages the number of pages of memory in the buffer cache
* @param lockManager the lock manager
* @param policy eviction policy for buffer cache
*/
public Database(String fileDir, int numMemoryPages, LockManager lockManager,
EvictionPolicy policy) {
this(fileDir, numMemoryPages, lockManager, policy, false);
}
在创建一个Database的过程中,需要初始化两个特殊的表:
- table_info:记录该database下每张表的元数据
- index_info:记录该database下每张索引表的元数据
// ...
if (!initialized) {
// _metadata.tables partition, and _metadata.indices partition
diskSpaceManager.allocPart(1);
diskSpaceManager.allocPart(2);
}
if (!initialized) {
this.initTableInfo();
this.initIndexInfo();
} else {
this.loadMetadataTables();
}
// ...
其中,table_info表初始化方法如下,可以看到该表位于part1文件上,有四列,其中的schema列最为关键。
// create _metadata.tables
private void initTableInfo() {
long tableInfoPage0 = DiskSpaceManager.getVirtualPageNum(1, 0);
diskSpaceManager.allocPage(tableInfoPage0);
LockContext tableInfoContext = new DummyLockContext("_dummyTableInfo");
PageDirectory tableInfoPageDir = new PageDirectory(bufferManager, 1, tableInfoPage0, (short) 0,
tableInfoContext);
tableMetadata = new Table(TABLE_INFO_TABLE_NAME, getTableInfoSchema(), tableInfoPageDir,
tableInfoContext, stats);
}
public Schema getTableInfoSchema() {
return new Schema()
.add("table_name", Type.stringType(32))
.add("part_num", Type.intType())
.add("page_num", Type.longType())
.add("schema", Type.byteArrayType(MAX_SCHEMA_SIZE));
}
Index_info表初始化方法如下,可以看到该表位于part2文件上,有8列。
// create _metadata.indices
private void initIndexInfo() {
long indexInfoPage0 = DiskSpaceManager.getVirtualPageNum(2, 0);
diskSpaceManager.allocPage(indexInfoPage0);
LockContext indexInfoContext = new DummyLockContext("_dummyIndexInfo");
PageDirectory pageDirectory = new PageDirectory(bufferManager, 2, indexInfoPage0, (short) 0,
indexInfoContext);
indexMetadata = new Table(INDEX_INFO_TABLE_NAME, getIndexInfoSchema(), pageDirectory, indexInfoContext, stats);
}
public Schema getIndexInfoSchema() {
return new Schema()
.add("table_name", Type.stringType(32))
.add("col_name", Type.stringType(32))
.add("order", Type.intType())
.add("part_num", Type.intType())
.add("root_page_num", Type.longType())
.add("key_schema_typeid", Type.intType())
.add("key_schema_typesize", Type.intType())
.add("height", Type.intType());
}
可以看到,在rookiedb中元数据也是存储在普通表中的,那么如果系统在启动的时候database已经创建好,它是如何进行boot的?换句话说,rookiedb的元数据使用普通表来存储,那么对元数据进行解析,需要它的元数据,元数据的元数据在哪里存储?如何解决“鸡生蛋,蛋生鸡”的问题?
这个问题的答案在loadMetaTables中,可以看到在加载这两张表的过程中,它们的schema是写死的(getTableInfoSchema,getIndexInfoSchema)。
private void loadMetadataTables() {
// Note: both metadata tables use DummyLockContexts. This is intentional,
// since we manually synchronize both tables to improve concurrency.
// load _metadata.tables
LockContext tableInfoContext = new DummyLockContext("_dummyTableInfo");
PageDirectory tableInfoPageDir = new PageDirectory(bufferManager, 1,
DiskSpaceManager.getVirtualPageNum(1, 0), (short) 0, tableInfoContext);
tableMetadata = new Table(TABLE_INFO_TABLE_NAME, getTableInfoSchema(), tableInfoPageDir,
tableInfoContext, stats);
// load _metadata.indices
LockContext indexInfoContext = new DummyLockContext("_dummyTableInfo");
PageDirectory indexInfoPageDir = new PageDirectory(bufferManager, 2,
DiskSpaceManager.getVirtualPageNum(2, 0), (short) 0, indexInfoContext);
indexMetadata = new Table(INDEX_INFO_TABLE_NAME, getIndexInfoSchema(), indexInfoPageDir,
indexInfoContext, stats);
indexMetadata.setFullPageRecords();
}
Disk
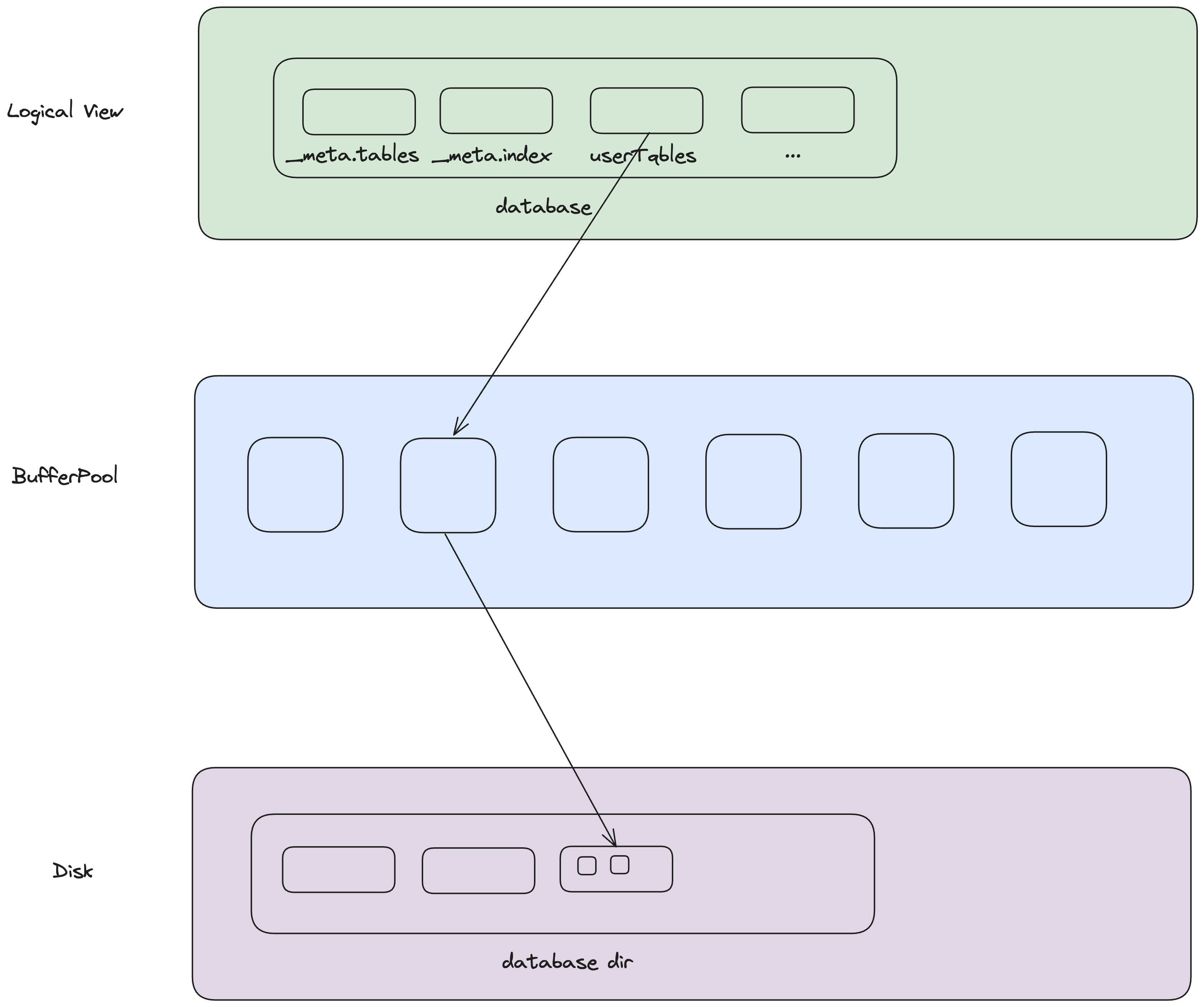
DiskSpaceManager负责管理磁盘上的文件,最终database的所有数据都需要写入磁盘的文件上。
rookieDB中,每个database存储在一个单独的目录下,database中的每张表存储在一个单独的文件中,每个文件对应一个Partition。
Partition下有多个DataPage,使用MasterPage -> HeaderPage -> DataPage的三层结构进行管理。
- MasterPage可以看作是一个integer数组,记录了每一个HeaderPage下DataPage的个数。
- HeaderPage可以看作是一个bitmap,其中的每一个bit对应DataPage的存在与否。
- DataPage就是一个4K bytes的块。
所以一个Partition看起来是这样的:
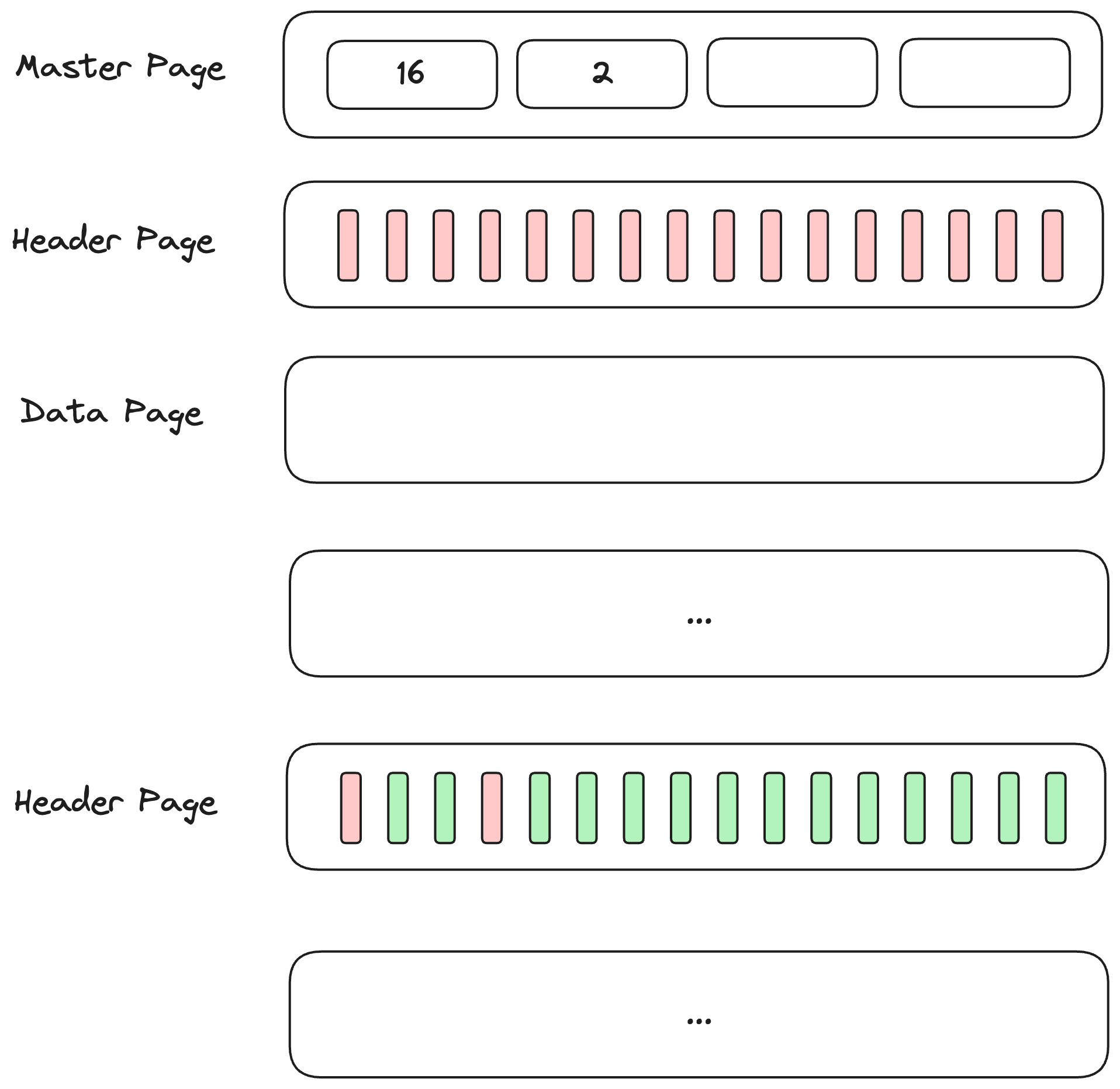
Put It Together