CS186 事务之故障恢复
原文:https://cs186berkeley.net/notes/note14/
动机
在之前的章节我们讨论了事务的ACID特性。在本章我们将会讨论如何让我们的数据库能够容忍故障(resilient to failures)。我们将会学习如何实现ACID中的D和A这两个特性:
- 持久性(Durability):一旦一个事务提交,它的结果就不会丢失。
- 原子性(Atomicity):事务中的操作要么全部执行,要么全都不执行。这意味着我们不会将数据库的状态搞到中间态。
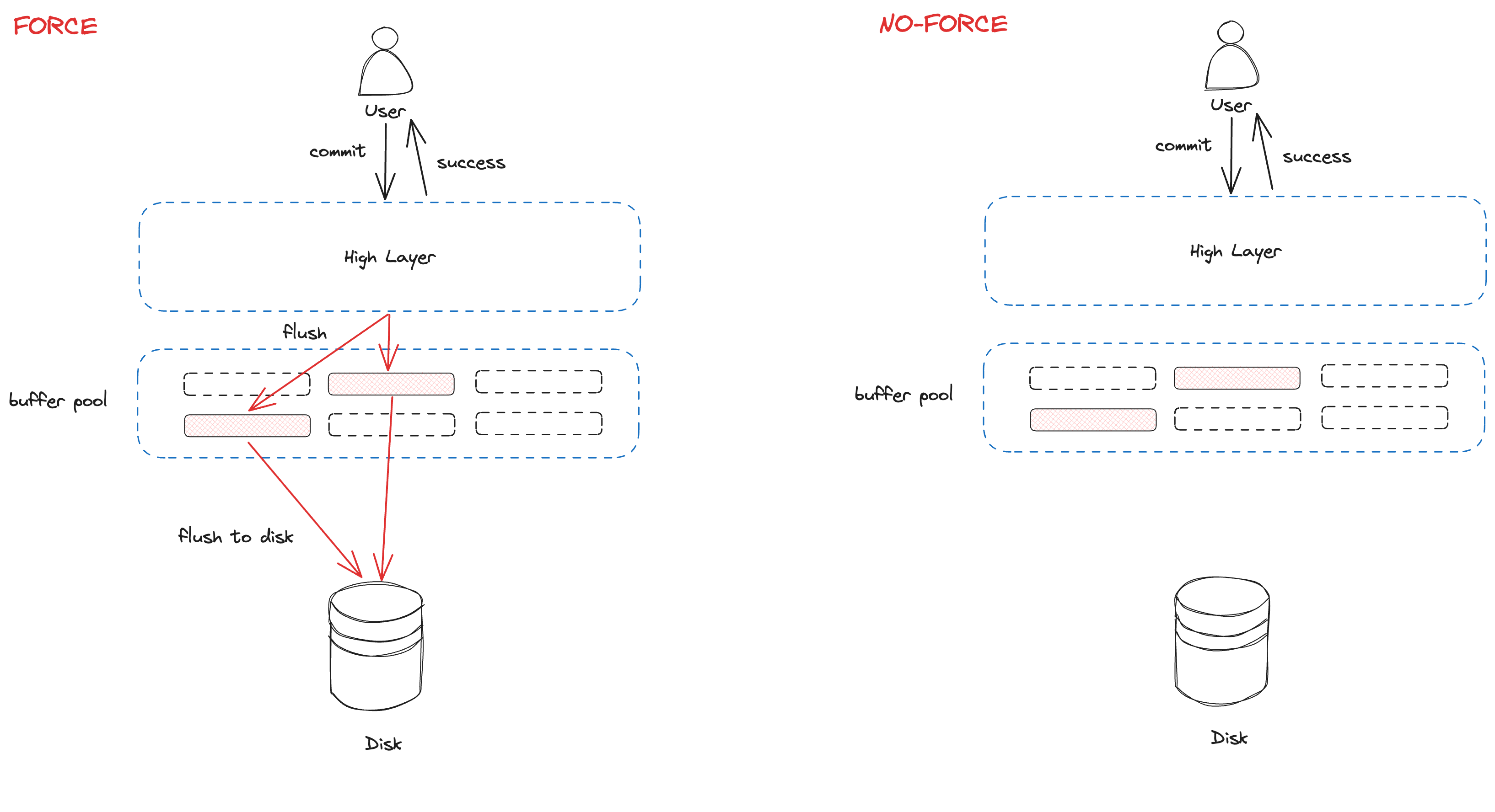
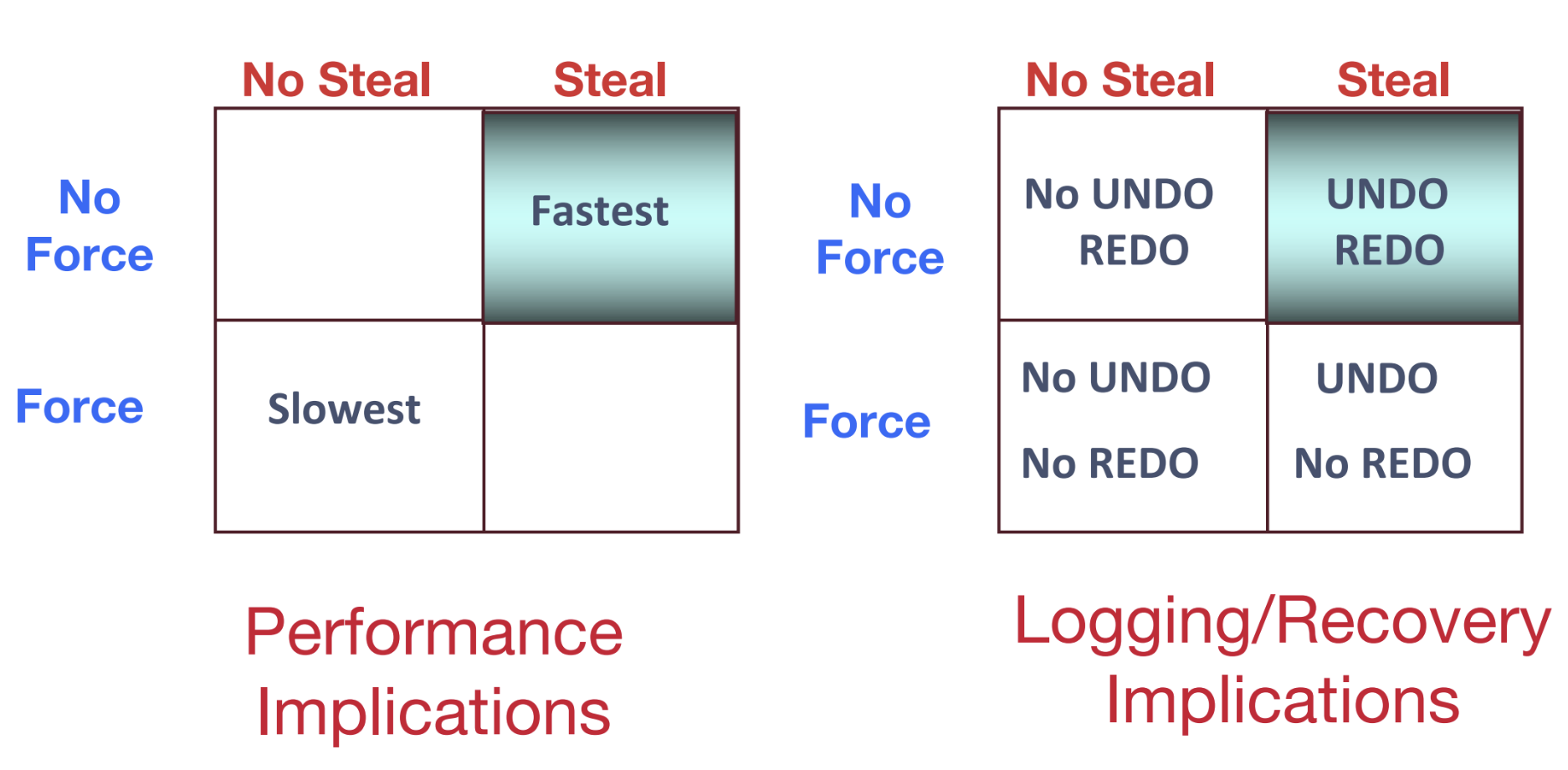
Force / No Force
如果我们使用force策略的话,就能够非常容易地保证持久性。==force策略的意思是:当一个事务结束时,在事务提交之前,强制将所有更改的数据页写到磁盘上。== 因为磁盘是非易失的,所以这样做能够保证持久性。换句话说,一旦一个页被写入磁盘,它就会被持久化地保存。
这样做的缺点是性能太差,因为我们会做很多不必要的写磁盘操作。在实际中,我们经常使用的是==No force策略,也就是当页从buffer pool中驱逐出去的时候,才会写回磁盘。==这样做会减少不必要的写,但是它让持久性变得更加复杂了,因为如果一个事务提交之后数据库挂了,还在buffer pool中的那些页就没办法写回磁盘了,它们就丢失了,因为内存是volatile的。为了解决这个问题,我们需要在恢复阶段重做(redo)一些操作。
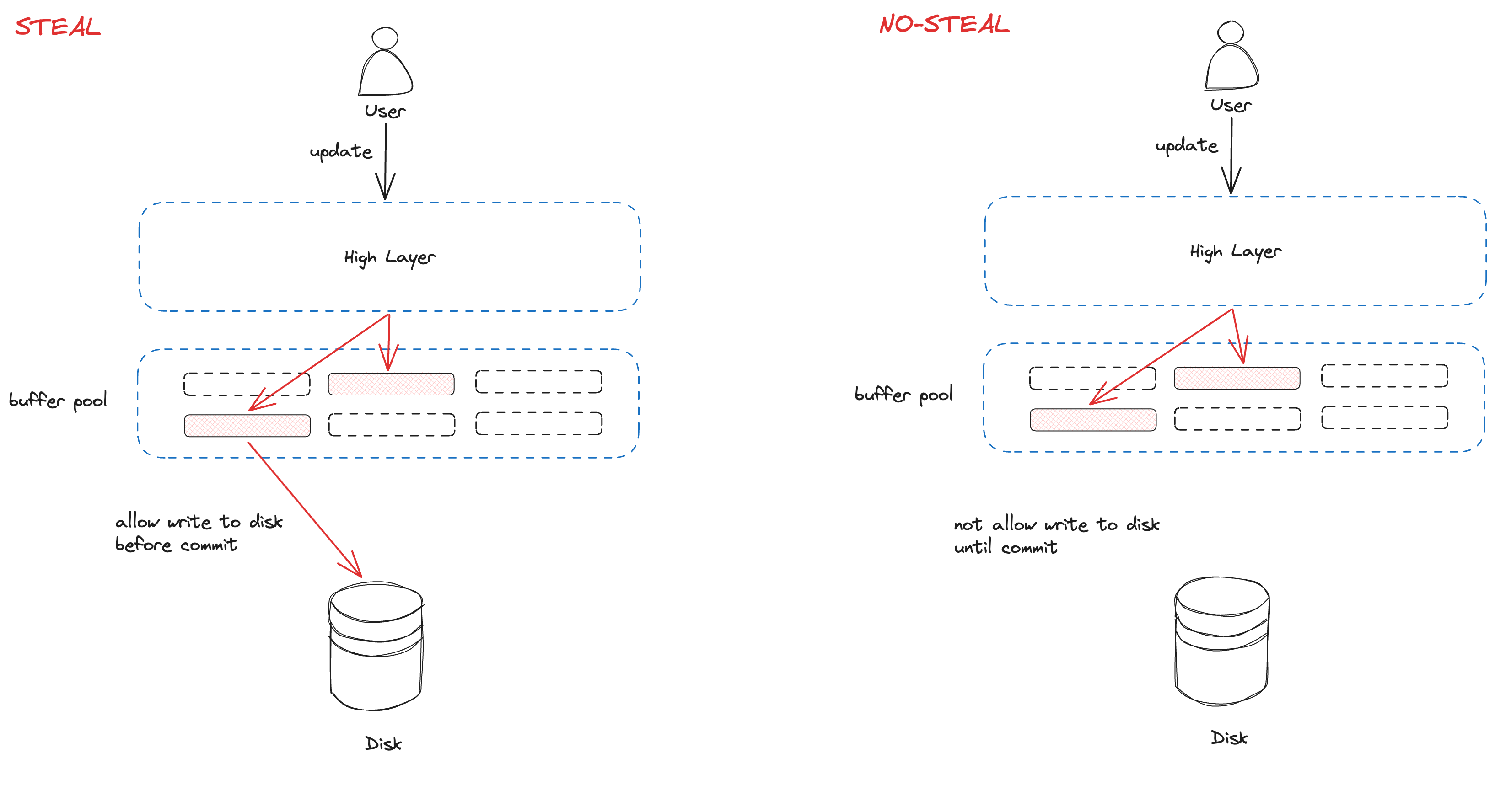
Steal / No Steal
使用No steal策略可以很容易地保证原子性。==No steal策略的意思是:在事务提交之前,页不能被驱逐出内存(因此被写回磁盘)。==
这样能够确保我们不会将数据库的状态搞到一种中间状态,因为如果事务没有结束,那么它所做的更改就都没有实际写到磁盘上。
这种策略的缺点是它比较消耗内存,因为我们必须在事务提交之前,将修改的所有页都保存在内存中。
在实际中,我们使用的一般是Steal策略,即在事务提交之前允许将一些修改的页写回磁盘。这对确保原子性带来了一些麻烦,但是我们可以通过在恢复阶段撤销(undo)所有的坏操作,来解决这个问题。
Steal, No Force
在实际中为了性能考虑,一般用的都是Steal + No Force的策略。本章的剩余部分将会介绍如何在使用Steal + No Force的策略的情况下确保原子性和持久性。
Write Ahead Logging
为了解决上面的问题,我们使用日志。日志是一个日志记录的序列,记录对数据库所做过的操作。
更新日志记录
每一个写操作(SQL insert/delete/update)将会在日志中对应一个UPDATE记录。
一个UPDATE记录看起来像下面这样:
<XID, pageID, offset, length, old_data, new_data>
- XID:事务ID(transaction ID),告诉我们哪个事务做的这个操作。
- pageID:哪个page被修改了
- offset:要被修改的数据在page内的页内偏移(通常单位是bytes)
- length:总共有多少数据被修改了(通常单位是bytes)
- old_data:原始数据是什么(用来undo操作)
- new_data:新数据是什么(用来redo操作)
其他日志记录
在我们的日志中,还有一些其他类型的记录:
- COMMIT:表明一个事务开始执行事务提交阶段
- ABORT:表明一个事务开始执行回滚事务阶段
- END:表明一个事务结束了(通常意味着完成了事务的提交或者回滚)
疑问🤔:
- 什么时候在日志中写COMMIT/ABORT?什么时候在日志中写END?COMMIT -> END之间,做了什么?
- 为什么没有事务开始的标志BEGIN?
WAL的需求
就像普通的数据页一样,日志页也需要在内存中操作,并且需要写回到磁盘上,以实现持久保存。Write Ahead Logging (WAL)带来了一个问题,那就是我们何时需要将日志写回磁盘。简单来说,write ahead logging是一个策略,即日志记录描述了一个如修改一个数据页、提交一个事务等这样的动作,这些==日志记录需要在实际动作被刷新到磁盘上或者发生之前写入到磁盘上==。两条规则如下:
- ==日志记录必须在相应的数据页写到磁盘上之前写到磁盘。==这是我们实现原子性的关键。如果数据页首先被写到了磁盘上,然后数据库挂了,那么我们就没有办法回滚那些操作了,因为我们根本不知道发生了什么。
- ==事务相关的日志记录必须在提交的时候保证都写到磁盘。== 这是我们实现持久性的关键。因为在事务提交成功之后可能还有一部分数据在buffer pool里,没有写到磁盘上(no-force)。假如这个时候数据库挂了,那么在buffer pool里的这部分修改就会丢失。如果我们能够保证事务提交成功之前,相关的日志都写到了磁盘上,那么我们就可以在故障恢复阶段利用日志来重做那些修改,这样就可以让数据库的状态恢复到发生故障之前。
WAL的实现
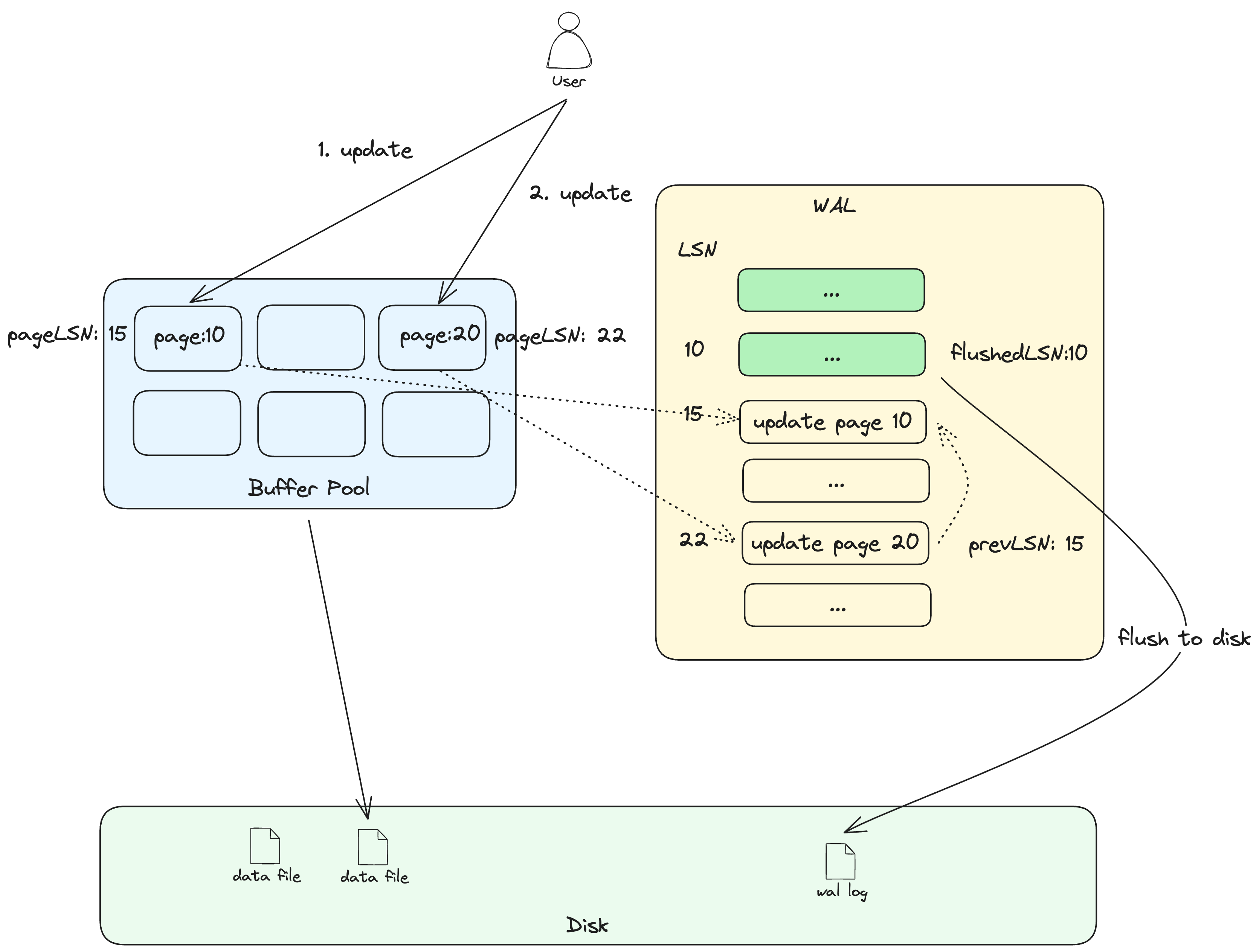
为了实现WAL,我们需要==给每个日志记录增加一个field,称为LSN(Log Sequence Number)==。LSN是一个唯一递增的数字,帮助指明操作的前后顺序。(比如,如果你看到一个LSN=20的操作,那么它发生在LSN=10对应的操作之后)。
在本文中,LSN每次增加10,但是这只是为了方便。我们还会给每一个日志记录增加一个prevLSN字段,它表示同一个事务中,当前这个操作的前一个操作对应的LSN。(这将会对回滚一个事务有所帮助)。
数据库还在内存中保存flushedLSN。==flushedLSN记录了最后一个被写入磁盘的记录所对应的LSN。==如果一个页是flushed,这意味着这个页已经被写到磁盘中了。通常也意味着我们可以从内存中驱逐出这一页,因为我们之后不会再需要它了。
flushedLSN告诉我们在它之前的所有日志记录都不用写到磁盘中了,因为这些内容已经写到磁盘了。在磁盘上,日志页通常会追加到上一个页之后。所以将相同的日志写多次,意味着我们在存储重复的数据,这也会破坏日志的连续性。
我们还会给每一个数据页增加一些元数据,比如pageLSN。pageLSN存储了上一个更新这个页的操作的LSN。我们用它来得知哪一个操作把它写回了磁盘,以及哪些操作必须要重做。
Cheatsheet:
- LSN:每个日志记录对应的编号
- prevLSN:前一个操作的LSN
- flushedLSN:最后一个被写入磁盘的记录的LSN
- pageLSN:上一个更新这个页的操作的LSN
小测试
Q:在页i允许被刷到磁盘上之前,下面这个式子应该填入哪种不等关系?
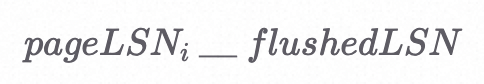
A:<=,这是我们WAL规则的第一条——我们必须在将数据页写到磁盘上之前,先把所有的日志记录写到磁盘上。一个数据页,只有当最后一个更改它的操作所对应的LSN小于或等于flushedLSN时,才能够刷到磁盘上。换句话说,在页i能够刷到磁盘上之前,所有更改页i的操作所对应的日志记录必须首先刷到磁盘上。
事务的回滚
在讲解数据库如何从故障中恢复之前,我们先来看一下数据库如何在正常的执行过程中回滚一个事务。
数据库选择回滚一个事务可能是由于多种原因,比如发生了死锁,或者该事务执行的时间太长所以用户决定回滚,或者是因为一个操作违反了ACID中的C(consistency),或者是由于系统crash导致事务需要被回滚等等。我们需要保证一旦回滚操作完成,磁盘上就没有那些被回滚事务所做的操作了。
回滚以及CLR记录
在回滚操作之前,我们需要首先在日志中添加一条ABORT记录,表明我们当前开始进行回滚操作。
接下来,我们==从日志中有关于这个事务的最后一个位置开始,undo这个事务的所有操作,并为每一个已经完成的undo操作在日志中添加一条CLR(Compensation Log Record)记录。==CLR是一个新的日志记录类型,表明我们正在做一个undo操作。从本质上来说,它和UPDATE记录是一样的,但是它告诉我们这是由于事务回滚所以才做的这个写操作。
疑问🤔:
在日志中添加ABORT记录之后,就可以通知用户事务回滚完成了吗?
我的想法:
和日志中的COMMIT是一个事务提交的唯一标志一样(意思:你在日志中看到了一个事务相关的commit,那么DBMS就一定要保证这个事务提交了),ABORT也是一个事务回滚的唯一标志。用户提交一个abort之后,把buffer pool中的数据更改一下,然后在WAL中写入ABORT之后就可以向用户返回abort_success了。如果在将buffer pool中数据写到磁盘之前数据库挂了,那么可以在故障恢复阶段看到日志中的ABORT之后,再执行undo。
回滚相关的数据结构
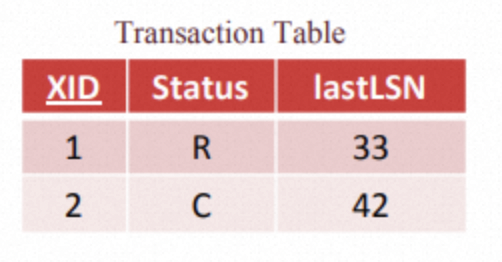
为了让恢复更加简单一些,我们会维护两个状态相关的表。第一个表叫做事务表(transaction table),它保存了当前系统内的活跃事务。这个表有三列:
- XID:事务ID
- status:事务状态,running / committing / aborting
- lastLSN:事务最近一次操作所对应的LSN
下面是事务表的一个例子:
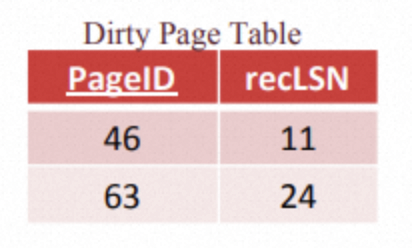
我们维护的另一个表称为脏页表(DPT, Dirty Page Table)。DPT记录了那些页是脏页(更改还在内存中,没有刷到磁盘上)。它可以告诉我们哪个页有还没有写到磁盘上的数据。DPT表只有两列:
- Page ID
- recLSN:the first operation to dirty the page
下面是DPT的一个例子:
需要注意的是,这两张表都是在内存中的,所以在进行故障恢复的时候,我们必须使用日志来重建这两张表。在稍后我们会讲解check pointing技术,它会让事情变得简单一些。
更多的小测试
Q1:(提示:需要保证在事务提交之前将所有日志刷到磁盘上)
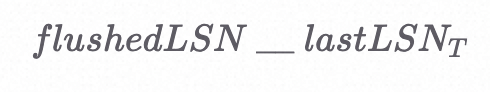
A1:>=
如果flushedLSN比事务的最后一个操作对应的LSN要大,那么我们就可以确信,在日志中这个事务对应的所有操作都在磁盘上了。
Q2:对于DPT中的页P来说,下面这个不等式应该满足什么关系?
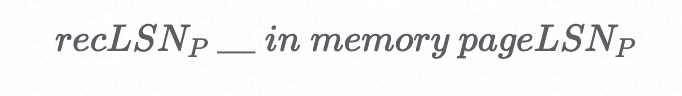
A:<=
如果一个页在DPT中,那么它一定是脏页,对这个脏页的最后一个更新一定没有被刷到磁盘上。recLSN是对这个脏页进行修改的第一个操作,所以它一定比对这个脏页进行修改的最后一个操作要小。
Q3:对于DPT中的页P来说,下面这个不等式应该满足什么关系?
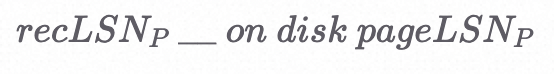
A:>
如果一个页是脏页,那么将这个页搞脏的那个操作(recLSN)一定还没有写到磁盘上,所以它一定比最后一个写到磁盘上的那个操作要小。
Undo Logging
上面我们啰嗦了很多关于数据库如何写WAL日志,以及在运行正常的时候如何回滚一个事务。现在,让我们来回到写日志的终极原因上:故障恢复。一种可行的恢复机制是Undo Logging。注意,Undo Logging并不是用我们前面提到的WAL。它使用的是force 和 steal机制。
Undo Logging的思想是,我们想要将那些还没有提交的事务所产生的影响回滚掉,同时对于已提交的事务啥也不做。
为了达到这样的效果,我们在日志中维护四种类型的记录:Start,Commit,Abort和Update(包含old value)。同时,关于如何记录日志,以及何时将脏数据页写到磁盘上,我们需要设立两个规则:
- 如果一个事务修改了一个数据项,那么这个更新所对应的日志记录必须先于脏页写磁盘。这是因为我们想要确保在使用新值持久性地替换老值之前,先将老值在磁盘上记录下来。
- ==如果一个事务提交,那么它修改的页必须在commit记录写到磁盘上之前先写到磁盘上==。这保证了事务在真正提交之前,它所做的所有改动都已经被写到磁盘上。这很关键,因为如果我们在日志中看到了一个commit记录,那么我们就会将这个事务视作已经提交,并且在恢复阶段不会对它做任何的undo处理。注意这里和WAL的一些细微的差别。
第一条规则对应的是steal策略,因为我们在一个事务提交之前就可以将部分修改写到磁盘上。第二条规则对应的是force策略。
有了上述两条规则,我们下面可以来讨论使用undo logging进行故障恢复了。当系统发生故障之后,我们首先运行故障恢复管理器(recovery manager)。我们从后向前扫描日志,通过扫描到的日志项,判断事务是否已经提交了:
- COMMIT/ABORT T:将T标记为完成
- UPDATE T, X, v:如果T还没有完成,将X=v写到磁盘,否则啥也不干
- START T:忽略
那么我们需要扫到啥时候才可以停止呢?需要一直扫到头,除非我们有check pointing技术(稍后讨论)。
下面是一个小例子,通过这里例子可以帮助我们理解Undo Logging恢复的过程。
总结:在undo logging恢复策略下(也即是使用force + streal策略),log中的ABORT和COMMIT即代表真正完成了ABORT或者COMMIT(事务相关的数据全部写到了磁盘上),也就是一个事务结束的标志。在undo logging中,事务结束就是真正的结束,所以不需要进行redo。但是由于采用的是streal策略,所以活跃事务的一部分数据可能写到了磁盘上,所以需要进行undo。
Redo Logging
下面来讨论一下基于日志的故障恢复的另一种策略:Redo Logging。Redo Logging采用了no-force和no-steal策略。在Redo Logging中,日志中的记录的类型和Undo Logging相同,唯一不同的是Update记录,在Undo Logging中它存储的是旧值,在Redo Logging中存储的是新值。
Redo Logging的思想和Undo Logging类似,不同点在于在恢复期间,不是将不完整的事务进行undo,而是将所有已经提交的事务进行redo。与此同时,不管那些还没有提交的事务。
与Undo Logging类似,这里也有一个规则:
- 如果一个事务修改了一个数据项X,那么日志中的update记录和commit记录都必须在写脏页之前写到磁盘上——这是no-steal策略。因此,脏页是在事务的commit记录之后写入磁盘的,这实际上就是WAL。
思考🤔:
- redo logging采用no-force策略,这意味着已提交的事务所做的修改可能还没有完全写到磁盘上。所以当我们在log中看到一个commit之后,还需要对它进行redo。
- redo logging采用no-steal策略,并且规定写脏页之前必须先向日志中写update记录和commit记录。这意味在事务提交之前,是可以确保没有任何的脏数据写到磁盘上的。我猜测事务提交的过程是这样的:用户在事务中提交的所有修改,都先写到buffer pool中,然后用户发送commit指令,DBMS开始提交这个事务。DBMS先把这些update对应的日志写到log中,然后再记一条commit。这个commit落盘之后即可向用户返回commit成功,后续可以慢慢将脏数据写到磁盘。
Redo Logging的故障恢复非常简单:我们从日志开头开始读取,将所有已经提交的事务重做一遍。虽然这样看起来需要很多操作,但是它可以通过check pointing技术进行优化。
下面是一个小例子:
ARIES 恢复算法
当一个数据库挂了之后,它在重启之后所能访问的只有之前写到磁盘上的日志,以及磁盘上的那些数据页。通过这些信息,它需要进行故障恢复,以使得所有已提交的事务所做的修改都被持久化(durability),并且正确地回滚那些在故障发生之前没有结束的事务(atomicity)。
恢复算法包含以下三个阶段:
- 分析阶段:构建出事务表(Xact table)和脏页表(DPT)
- Redo阶段:重复执行操作,以保证持久性
- Undo阶段:回滚在发生故障时还在运行的事务,以保证原子性
下面我们来逐个讲解每个阶段。
分析阶段
==整个分析阶段的目的是为了构造出发生故障时系统中的事务表和脏页表。==我们需要从日志的开头扫描所有的记录,并且依据以下规则来更新我们的表:
- 对于所有不是END的记录:将事务添加到事务表中(如果需要的话),并且更新lastLSN字段
- 如果记录是COMMIT或者ABORT:更改事务表中事务对应的状态
- 如果记录是UPDATE:如果该页不在DPT表中,则将这个页加入DPT,并将recLSN设置为这个记录的LSN
- 如果记录是END:将事务从事务表中移除
在分析阶段的最后,对于所有提交中的事务(any transactions that were committing),我们会在日志的最后添加一个END记录,然后将事务从事务表中移除。此外,在发生故障时正在执行的事务需要进行回滚,并且需要在日志中记录回滚。
目前来看,分析阶段的一个问题是需要扫描所有的日志。对于生产环境而言这是无法接受的,因为整个扫描阶段的耗时是不确定的,可能只需要几百毫秒,也可能需要几千秒。为了加速这个过程,我们使用checkpointing技术。checkpointing技术将事务表和DPT写到日志中。通过这样做,我们可以不用从日志的开头,而是从最后一个checkpoint开始处理日志。
在本章的剩余部分,我们引入checkpointing的一个变种,称为fuzzy checkpointing。它实际上向日志中写了两条记录:一个<BEGIN_CHECKPOINT>记录,表示开始进行checkpointing,还有一个<END_CHECKPOINT>记录,表示已经将表写入了日志中。
在日志中实际写入的表,可能是<BEGIN_CHECKPOINT>和<END_CHECKPOINT>之间任意时刻的值。这意味着我们需要在<BEGIN_CHECKPOINT>开始处理日志,因为我们无法确定日志中表所对应的准确的点。
分析阶段例子
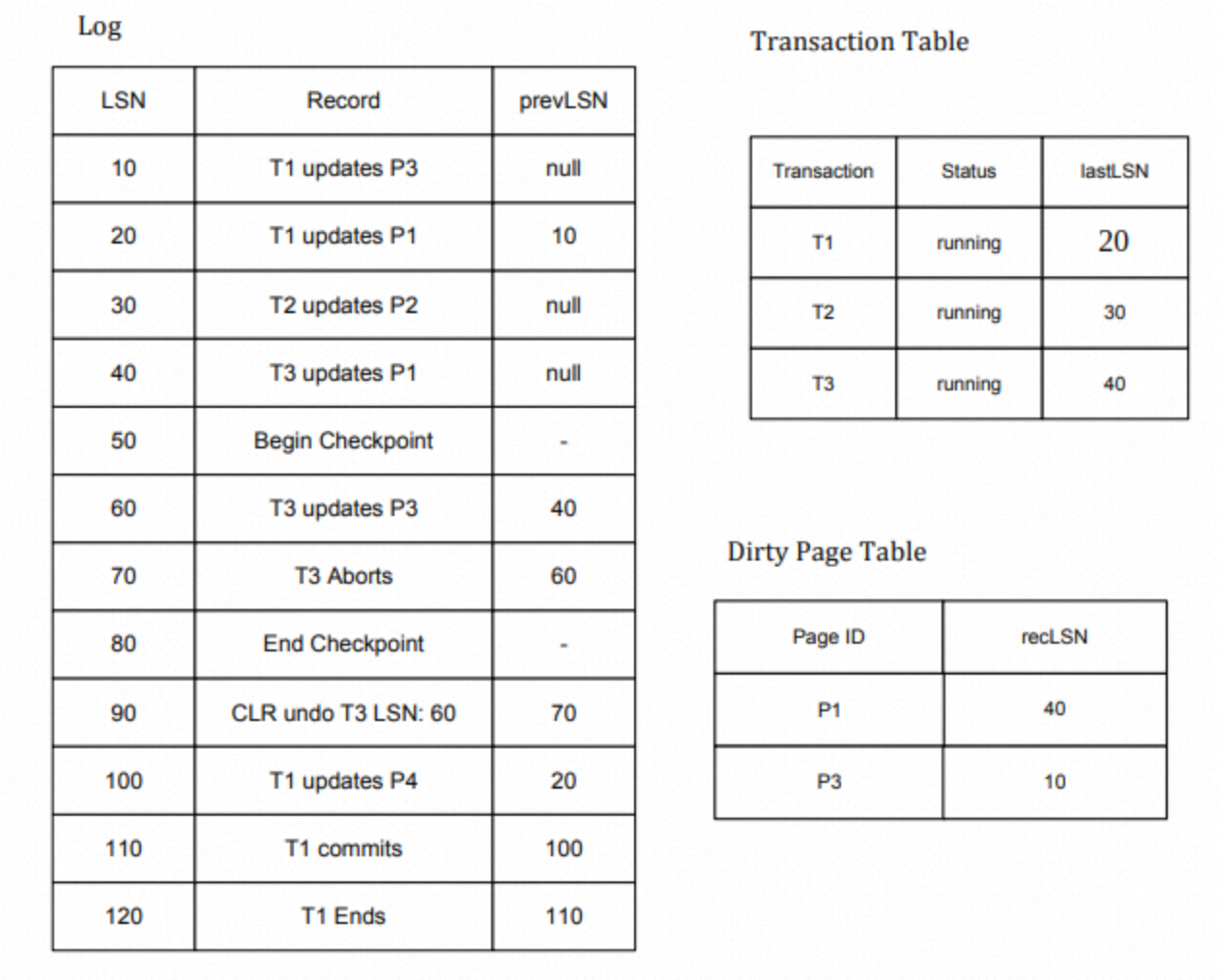
假如数据库挂了,然后给了我们如上图所示的日志。图中右侧的事务表和脏页表是在<END_CHECKPOINT>记录中找到的。下面让我们一起手动模拟一下分析阶段。
首先,我们需要从LSN=60这个地方开始进行处理,因为它是<BEGIN_CHECK_POINT>记录后的第一条记录。这是一个UPDATE的记录,T3已经在事务表中了,所以我们需要更新lastLSN字段为60。因为60这个记录所更新的页P3已经在DPT中了,所以对于DPT我们什么也不用做。处理完60,表的状态如下:
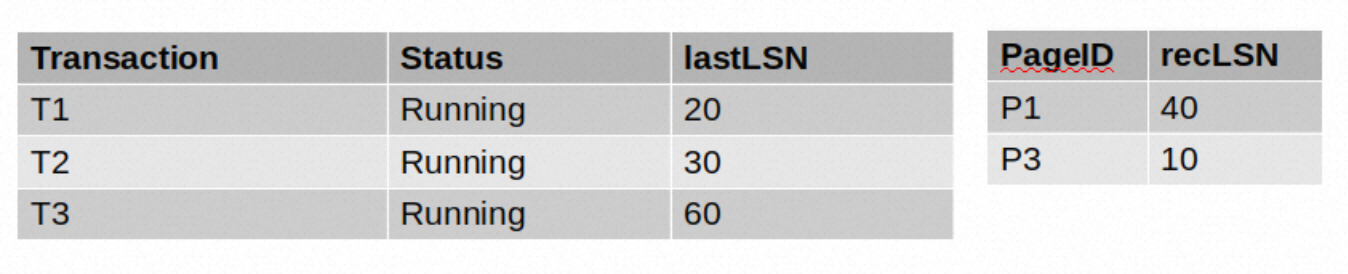
接下来处理LSN=70所对应的记录。这是一个ABORT记录,所以我们需要将事务表中的事务状态更新为Abort,并更新相应的last LSN。处理完70,表的状态如下:

80是<CHECK_POINT_END>,对于它我们什么也不用做。
下面是90,它是一个CLR,T3在事务表中,所以我们更新一下对应记录的lastLSN为90。这个CLR所操作的数据页(P3,从60可以看到)已经在DPT中,所以我们不用更新DPT了。
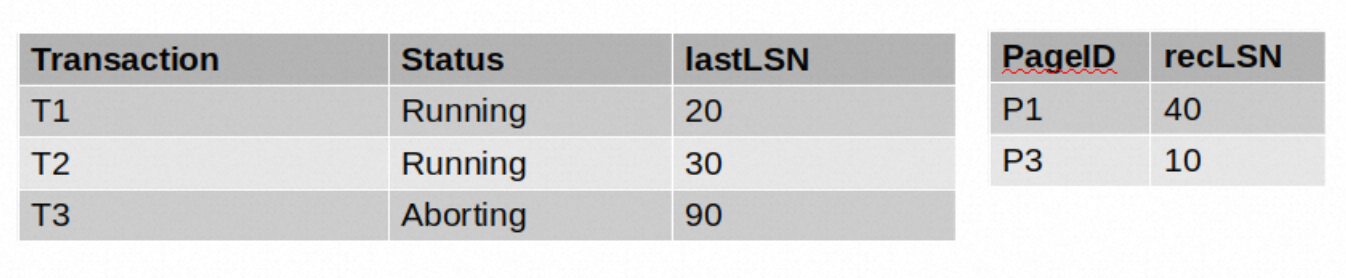
在100我们遇到了另一个更新操作。它所操作的事务T1已经在事务表中了,所以我们更新一下它对应的lastLSN为100。它所更新的页(P4)在DPT中没有,所以我们在DPT中插入一条记录<P4, 100>

110是一个COMMIT记录,我们需要将T1的状态改为Committing,并且更新lastLSN。
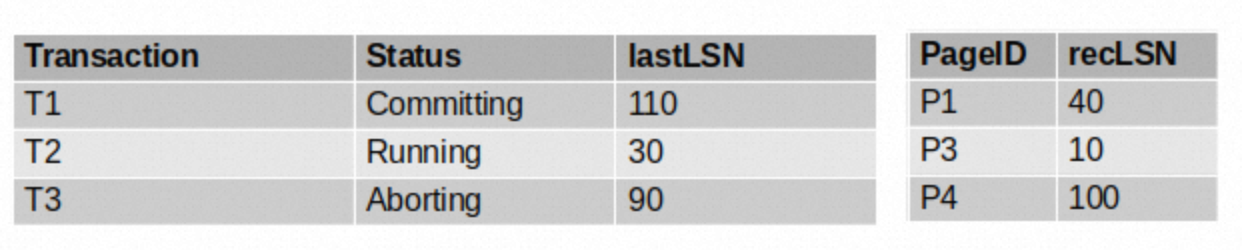
最后,LSN120是一个END记录,这意味着我们需要把T1从事务表中移除。

注意,在这个例子中我们省略了将提交中的事务状态改为结束,将运行中的事务状态改为回滚,因为前面已经做过几次相关的测试了。实际上,在进行Redo阶段之前,我们会将T2的状态改为Aborting。
Redo阶段
Redo阶段保证了持久性。我们会重演历史,以重构出发生crash时的状态。我们从DPT的最小recLSN开始,因为这是第一个可能没有持久化到磁盘的操作。我们会对所有的UPDATE和CLR进行redo,除非出现以下状况:
- 页不在DPT中。如果页不再DPT中,那么就意味着对它进行的所有修改都已经持久化到磁盘了。
- recLSN > LSN。因为DPT中记录的是第一个使得页变为脏页的记录,所以如果某个记录的LSN比recLSN小,那么它所做的修改已经持久化到磁盘了。(这条规则指出了我们应该从哪里开始进行redo)
- pageLSN(disk) >= LSN。如果最后一个对页进行更新,并刷新到磁盘的操作的LSN比当前LSN大,那么就代表当前操作肯定已经持久化了。
Redo例子
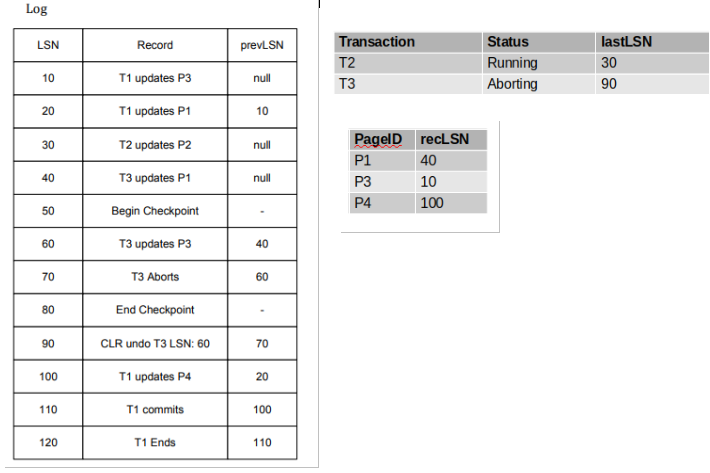
经过分析阶段之后,我们构造出的事务表和DPT如上图所示。我们首先需要思考两个问题:
- 我们应该从哪里开始进行恢复?
- 应该在LSN为10的地方开始,因为它是DPT中最小的recLSN。
- 我们需要redo哪些操作?
- 10:redo
- 20:不需要redo,因为它更新了P1,但是DPT中记录的P1对应的recLSN为40,所以它肯定已经持久化了
- 30:不需要redo,因为它更新的P2不在DPT中
- 40:redo
- 50:不需要redo,checkpoint
- 60:redo
- 70:不需要redo, abort
- 80:不需要redo,checkpoint
- 90:redo
- 100:redo
- 110:不需要redo, commit
- 120:不需要redo, end
Undo阶段
故障恢复的最后一个阶段是undo,它保证了原子性。undo阶段从后向前扫描日志,对故障发生时活跃的事务(running 或者 aborting)的所有UPDATE操作进行回滚,以保证我们不会将数据库的状态置为中间态。如果一个UPDATE已经被回滚了,那么就不需要再对它进行回滚(已经被回滚的UPDATE在日志中有一个CLR记录与之对应)。
对于undo阶段进行的每一个回滚操作,都会在日志中添加一条CLR记录。CLR记录有一个额外的字段,称为undoNextLSN。undoNextLSN记录了下一个需要进行undo的操作对应的LSN(它来自你正在进行undo的记录的prevLSN)。一旦你将一个事务的所有操作都回滚了,就需要在日志中为这个事务添加一个END记录。
附录1会详细解释如何高效地做这件事。
Undo例子
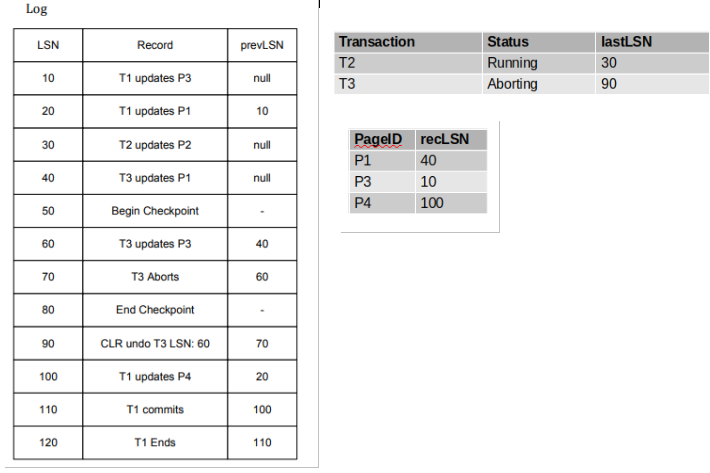
尝试写出在undo阶段需要在日志中记录的所有日志。
Answer:
首先需要注意到的是,我们在分析阶段少写了一个日志记录。在分析阶段的最后,我们需要对所有aborting的事务写一个日志,因此,我们需要在LSN=130的地方写一个针对事务T2的ABORT记录,它的prevLSN是30,因为这是T2在ABROT记录之前的最后一个操作。我们将添加这个记录放在这里讲,主要是为了教学的完整性。但是需要注意的是,这个记录不是在undo阶段写的,而是在分析阶段。
接下来我们要做的就是回滚事务T2和T3。T3的最后一个UPDATE在60,但是需要注意,LSN=90的地方已经有了一个针对它的CLR。这代表着LSN=60已经被回滚掉了,所以我们不会再重复回滚它。
下一个UPDATE在LSN=40。因为这个update在日志中没有对应的CLR,所以我们需要回滚它,然后在日志中记录一个CLR。CLR的prevLSN是90,因为90对应的这个CLR是T3事务的最后一个操作。undoNextLSN是null,因为在T3中再没有其他的操作需要回滚了。因为T3没有其他的操作需要回滚,所以我们在日志中记录一个END T3。
下一个需要回滚的操作是针对T2的30。CLR对应的prevLSN是130,因为它是我们之前为T2写的ABORT记录所对应的LSN。undoNextLSN也是null,因为在T2中再没有其他操作需要回滚了。最后我们再针对T2写一个END。
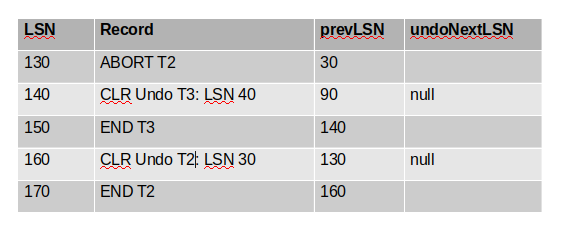
下面是最终答案:
总结
到此为止,我们就把ARIES恢复算法全部讲完了!回顾一下我们是怎么做到的。我们首先重建了数据库在发生crash之前的状态,这是通过重新构造事务表和脏页表,以及redo所有还没来得及flush的操作完成的。然后,通过一趟扫描,我们把发生crash之前正在运行的事务回滚掉了。下图展示了ARIES算法的三个阶段:
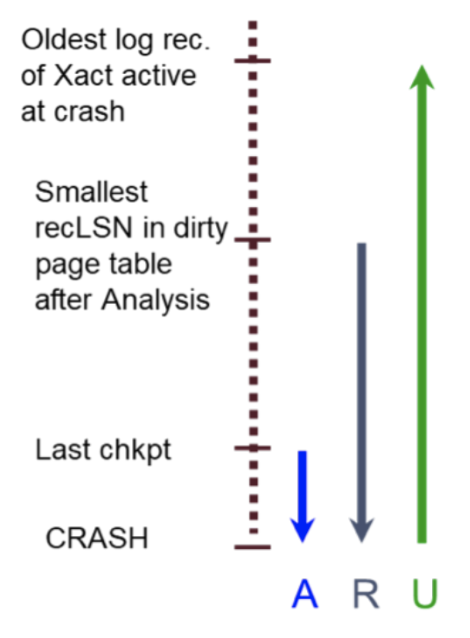
在本文中,我们介绍了数据库如何在使用streal, no-force策略下进行故障恢复。下面是采用不同策略对性能以及恢复方式影响的一个总结:
接下来我们介绍了数据库如何在正常运行的过程中使用WAL日志将它做的所有操作记录下来。最后我们讲解了数据库如何在三个阶段(分析,redo,undo)使用WAL日志来进行故障恢复。